
Video to text: automatic natural language description of video
In collaboration with UT Austin and UC Berkeley
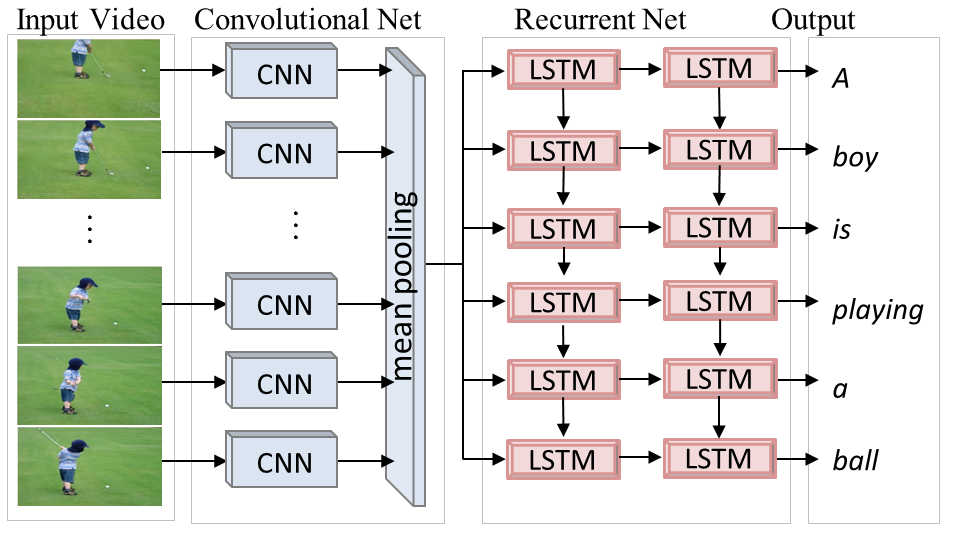
Many core tasks in artificial intelligence require joint modeling of visual data and natural language. The past few years have seen increasing recognition of this problem, with research on connecting words and names to pictures, storytelling based on static images, and visual grounding of natural-language instructions for robotics. This project focuses on generating natural language descriptions that capture sequences of activities depicted in diverse video corpora. The major obstacles to scalable "in-the-wild" video description are limited training data, extreme diversity of visual and language content, and lack of rich and robust representations. We tackle these obstacles by learning the underlying semantics of activities jointly from described video and from available text-only sources, and use them to both constrain visual recognition and to drive text generation.
Papers:
A Multi-scale Multiple Instance Video Description Network. Huijuan Xu, Subhashini Venugopalan, Vasili Ramanishka, Marcus Rohrbach, Kate Saenko. ICCV15 workshop on Closing the Loop Between Vision and Language
Long-term Recurrent Convolutional Networks for Visual Recognition and Description. Jeff Donahue, Lisa Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell. CVPR 2015. [Project Website & Code]
Translating Videos to Natural Language Using Deep Recurrent Neural Networks. Subhashini Venugopalan, Huijun Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko. NAACL 2015
Integrating language and vision to generate natural language descriptions of videos in the wild. J. Thomason, S. Venugopalan, S. Guadarrama, K. Saenko, and R. Mooney. In Proceedings of the 25th International Conference on Computational Linguistics (COLING), August 2014.
Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition. Sergio Guadarrama, Niveda Krishnamoorthy, Girish Malkarnenkar, Subhashini Venugopalan, Raymond Mooney, Trevor Darrell, and Kate Saenko; In IEEE International Conference on Computer Vision (ICCV) 2013. [dataset]